Las dos principales tecnologías de embalaje especializadas de Intel son EMIB y Foveros. Intel ha explicado el futuro de ambos en relación con su próximo desarrollo de nodos.
Junto con los avances del nodo de proceso, Intel también tiene que avanzar con la tecnología de empaque de próxima generación.
La demanda de silicio de alto rendimiento junto con el desarrollo de nodos de proceso cada vez más difícil ha creado un entorno en el que los procesadores ya no son una sola pieza de silicio.
Ahora dependen de múltiples chiplets o mosaicos más pequeños (y potencialmente optimizados) que se empaquetan juntos de una manera que beneficien rendimiento, potencia y producto final.
Los chips grandes individuales ya no son una decisión comercial inteligente: pueden resultar demasiado difíciles de fabricar sin defectos, o la tecnología para crearlos no está optimizada para ninguna característica en particular del chip.
Sin embargo, dividir un procesador en piezas de silicio separadas crea barreras adicionales para mover datos entre esas piezas.
Si los datos tienen que pasar de estar en silicio a estar en otra cosa (como un paquete o un intercalador), entonces hay un poder costo y costo de latencia a considerar.
La compensación es silicio optimizado construido para un propósito, como un chip lógico hecho en un proceso lógico, un chip de memoria hecho en un proceso de memoria.
Los chips más pequeños a menudo tienen mejores características de voltaje / frecuencia cuando se agrupan que sus contrapartes más grandes. Pero la base de este puzzle es cómo se unen las piezas.
Por ello en esta entrada vamos a intentar arrojar un poco de luz sobre el funcionamiento de EMIB, Foveros y Foveros Omni.
Contenidos
- 1 Puente de interconexión de múltiples matrices integrado (EMIB)
- 2 Foveros: apilamiento matriz a matriz
- 3 Foveros Omni: la tercera generación
- 4 Foveros Direct: la cuarta generación
- 5 Relacionados
- 5.1 Raspberry Pi 5: lanzamiento y características
- 5.2 Ventajas de solicitar un préstamo personal online
- 5.3 El camión con plataforma elevadora y su importancia en la ciudad
- 5.4 Los teléfonos reacondicionados: entre lo nuevo y la segunda mano o, ¿mejor?
- 5.5 Bicicletas inteligentes ¿Qué son y cuál es su futuro?
- 5.6 Implementación del APPCC Cocina: Mejores Prácticas y Beneficios de la Consultoría APPCC
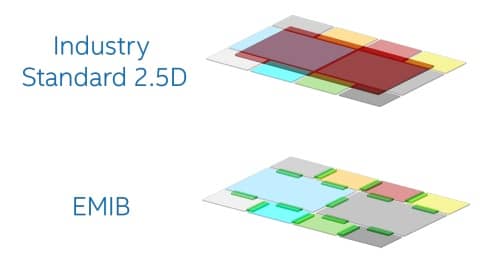
Puente de interconexión de múltiples matrices integrado (EMIB)
La tecnología EMIB de Intel está diseñada para conexiones de chip a chip cuando se coloca en un plano 2D.
La forma más fácil para que dos chips en el mismo sustrato se comuniquen entre sí es tomando una ruta de datos a través del sustrato.
El sustrato es una placa de circuito impreso hecha de capas de material aislado intercaladas con capas de metal grabadas en pistas y trazas.
Dependiendo de la calidad del sustrato, el protocolo físico y el estándar que se utilice, cuesta mucha energía transmitir datos a través del sustrato y se reduce el ancho de banda. Pero esta es la opción más barata.
La alternativa a un sustrato es colocar ambos chips en un intercalador. Un intercalador es una pieza grande de silicio, lo suficientemente grande para que ambos chips encajen por completo, y los chips se unen directamente al intercalador.
De manera similar, hay rutas de datos colocadas en el intercalador, pero debido a que los datos se mueven de silicio a silicio, la pérdida de energía no es tanto como un sustrato y el ancho de banda puede ser mayor.
La desventaja de esto es que el intercalador también debe fabricarse (generalmente a 65 nm), los chips involucrados deben ser lo suficientemente pequeños para caber y puede ser bastante costoso.
Pero, el intercalador es una buena solución, y los intercaladores activos (con lógica incorporada para redes) aún no se han explotado por completo).
La solución EMIB de Intel es una combinación de intercalador y sustrato. En lugar de utilizar un intercalador grande, Intel usa un pequeño deslizamiento de silicio y lo incrusta directamente en el sustrato, e Intel llama a esto un puente.
El puente es efectivamente dos mitades con cientos o miles de conexiones a cada lado, y los chips están construidos para conectarse a la mitad del puente.
Ahora ambos chips están conectados a ese puente, con la ventaja de transferir datos a través de silicio sin las restricciones que podría traer un intercalador grande.
Intel puede incrustar múltiples puentes entre dos chips si se necesita más ancho de banda, o múltiples puentes para diseños que usan más de dos chips. Además, el costo de ese puente es mucho menor que el de un intercalador grande.
Foveros: apilamiento matriz a matriz
Intel presentó su tecnología de apilamiento de troquel a troquel en 2019 con Lakefield, un procesador móvil diseñado para diseños de baja potencia inactiva.
Desde entonces, ese procesador se ha puesto en procedimientos de fin de vida útil , pero la idea sigue siendo parte integral del futuro de la cartera de productos y las ofertas de fundición futuras de Intel.
El apilamiento de matriz a matriz de Intel es, en gran medida, muy similar a la tecnología de interposición mencionada en la sección EMIB.
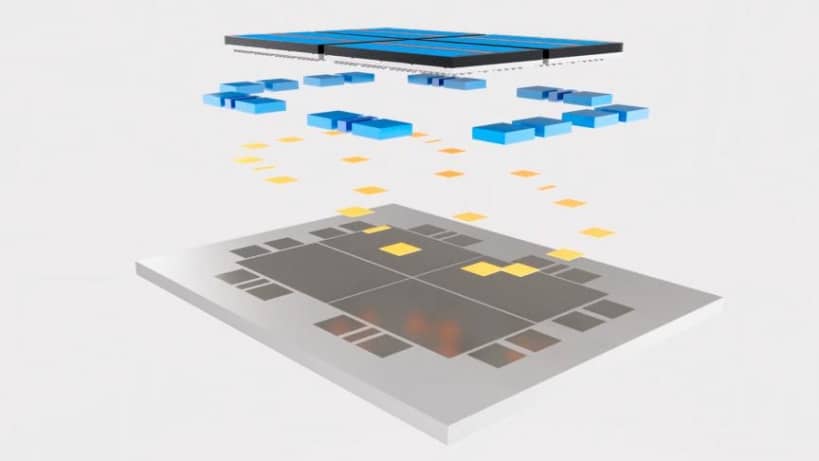
Tenemos una pieza de silicona (o más) encima de otra. En este caso, sin embargo, el intercalador, o matriz base, tiene un circuito activo relevante para el funcionamiento completo de los procesadores de cómputo principales que se encuentran en la pieza superior de silicio.
Si bien los núcleos y los gráficos estaban en el troquel superior en Lakefield, construido en el nodo de proceso de 10 nm de Intel, el troquel base tenía todos los carriles PCIe, puertos USB, seguridad y todo lo relacionado con el bajo consumo de energía IO, y se construyó con un 22FFL de bajo consumo.
Entonces, mientras que la tecnología EMIB que divide el silicio para trabajar uno al lado del otro se conoce como escalado 2D, al colocar el silicio uno encima del otro, hemos ingresado en un régimen de apilamiento 3D completo.
Esto viene con algunos buenos beneficios, especialmente a escala: las rutas de datos son mucho más cortas, lo que lleva a una menor pérdida de energía debido a cables más cortos, pero también a una mejor latencia.
Las conexiones de matriz a matriz siguen siendo conexiones unidas, con la primera generación en un paso de 50 micrones.
Pero aquí hay dos limitaciones clave: térmicas y de potencia. Para evitar problemas con las térmicas, Intel hizo que el dado base tuviera muy poca lógica y utilizó un proceso de baja potencia.
Con el poder, el problema es permitir que el dado de cómputo superior tenga poder para su lógica; esto implica una gran potencia a través de vías de silicio (TSV) desde el paquete hasta el dado base hasta el dado superior, y esos TSV que transportan energía se convierten en un problema de señalización de datos localizados debido a interferencias causadas por corrientes elevadas.
También existe el deseo de escalar a tonos más pequeños en procesos futuros, lo que permite conexiones de mayor ancho de banda, lo que requiere que se preste más atención a la entrega de energía.
El primer anuncio relacionado con Foveros hoy se refiere a un producto de segunda generación. El procesador de consumo de Intel 2023, Meteor Lake, ya se ha descrito anteriormente como un mosaico de cómputo Intel de 4 nm, aprovechando EUV.
Intel también ha declarado hoy que utilizará su tecnología Foveros de segunda generación en la plataforma, implementando un tono de golpe de 36 micrones, duplicando efectivamente la densidad de conexión con respecto a la primera generación.
El otro mosaico en Meteor Lake aún no se ha revelado (ya sea qué tiene o en qué nodo se encuentra), sin embargo, Intel también afirma que Meteor Lake escalará de 5 W a 125 W.
Foveros Omni: la tercera generación
Para aquellos que han estado siguiendo de cerca las tecnologías de empaque de Intel, entonces el nombre ‘ODI’ puede resultar familiar.
Significa Omni-Directional Interconnect, y fue el apodo que se usó en las hojas de ruta anteriores de Intel con respecto a una tecnología de empaque que permite el silicio en voladizo. Eso ahora se comercializará como Foveros Omni.
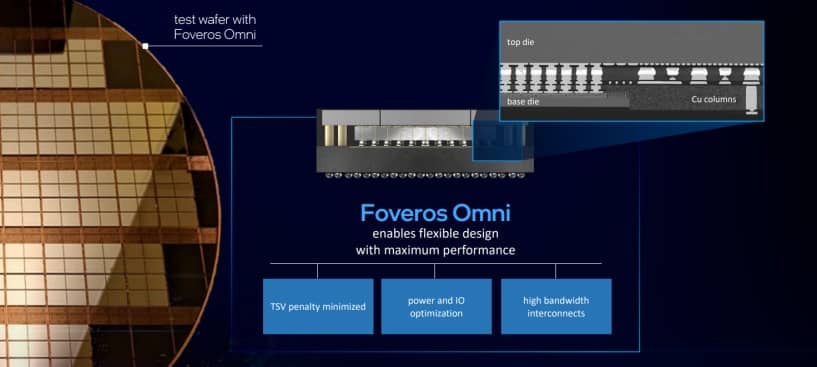
Esto significa que ahora se ha eliminado el límite de los Foveros de primera generación que necesitaban un troquel superior más pequeño que el troquel base. El troquel superior puede ser más grande que el troquel base, o si hay varios troqueles en cada uno de los niveles, se pueden conectar a cualquier otro silicio.
El objetivo de Foveros Omni es realmente resolver el problema de energía como se discutió en la sección inicial de Foveros, debido a que los TSV que transportan energía causan mucha interferencia localizada en la señalización, el lugar ideal para colocarlos sería en el exterior del dado base.
Foveros Omni es una tecnología que permite que el troquel superior sobresalga del troquel base y se construyen pilares de cobre desde el sustrato hasta el troquel superior para proporcionar energía.
Con esta tecnología, si se puede traer energía desde los bordes del troquel superior, entonces se puede utilizar este método.
Intel ha declarado que Foveros Omni funciona con matrices de base dividida, de modo que los pilares de cobre que transportan energía podrían colocarse en el medio del diseño si el La matriz base está diseñada para que el sustrato esté disponible en esa capa inferior.
Al mover los TSV de potencia fuera de la matriz base, esto también permite una mejora del paso de golpe de matriz a matriz.
Intel está citando 25 micrones para Omni, lo que sería otro 50% de aumento en la densidad de relieve sobre los Foveros de segunda generación y espera que Foveros Omni esté listo para la fabricación en volumen en 2023.
Foveros Direct: la cuarta generación
Uno de los problemas con cualquier conectividad de morir a morir es la conexión en sí. En todas estas tecnologías mencionadas hasta ahora, estamos tratando con conexiones unidas por microbombas: pequeños pilares de cobre con una tapa de soldadura de estaño, que se ensamblan y “se unen” para crear la conexión.
A medida que estas tecnologías hacen crecer el cobre y la soldadura de estaño que se deposita, se vuelve difícil reducirlas, además de que también existe la pérdida de potencia de los componentes electrónicos que se transfieren a los diferentes metales. Foveros Direct soluciona este problema mediante la unión directa de cobre a cobre.
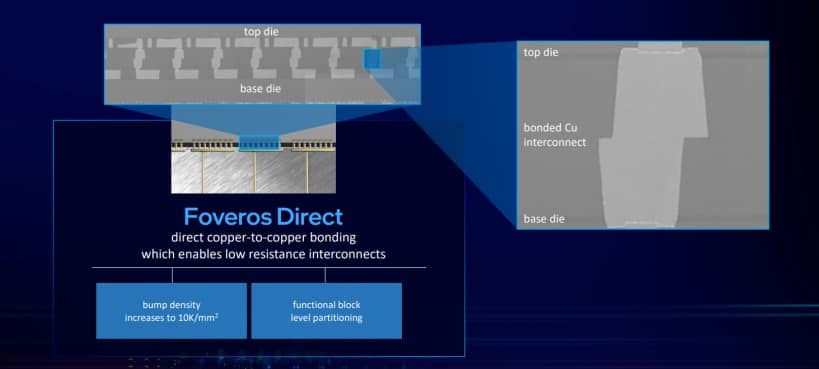
En lugar de depender de la unión de pilares y protuberancias, el concepto de conectividad directa de silicio a silicio se ha investigado durante varios años. Si una pieza de silicio se alinea directamente con otra, entonces hay poca o ninguna necesidad de pasos adicionales para hacer crecer pilares de cobre y demás.
El problema viene con asegurarse de que se realicen todas las conexiones, asegurando que tanto el dado superior como el inferior sean tan increíblemente planos que nada se interponga en el camino. Además, las dos piezas de silicio tienen que convertirse en una, y están unidas permanentemente sin ninguna forma de separarse.
Foveros Direct es una tecnología que ayuda a Intel a reducir el tono de golpe de sus conexiones de matriz a matriz hasta 10 micrones, un aumento de 6 veces en la densidad sobre Foveros Omni.
Al habilitar las conexiones planas de cobre a cobre, aumenta la densidad de impacto y el uso de una conexión totalmente de cobre significa una conexión de baja resistencia y se reduce el consumo de energía.
Intel ha sugerido que con Direct, la partición funcional de troqueles también se vuelve más fácil, y los bloques funcionales podrían dividirse en múltiples niveles según sea necesario.
Técnicamente, Foveros Direct como unión de matriz a matriz podría considerarse complementario de Foveros Omni con las conexiones de alimentación fuera de la matriz base; ambas podrían usarse independientemente una de la otra.
La vinculación directa facilitaría las conexiones eléctricas internas, pero quizás aún existiera el problema de la interferencia, de la que Omni se encargaría.
Cabe señalar que TSMC tiene una tecnología similar , conocida como Chip-on-Wafer (o Wafer-on-Wafer), y los productos de los clientes llegarán al mercado en los próximos meses utilizando pilas de 2 alturas.
TSMC ha demostrado una pila de 12 alturas a mediados de 2020, sin embargo, este fue un vehículo de prueba para señalización, en lugar de un producto. El problema que aumenta en las pilas seguirá siendo las térmicas y lo que entra en cada capa.
Intel augura que tanto Foveros Direct, como Omni, estarán listos para producirse en masa a lo largo de 2023.
Relacionados
-

Raspberry Pi 5: lanzamiento y características
-

Ventajas de solicitar un préstamo personal online
-

El camión con plataforma elevadora y su importancia en la ciudad
-

Los teléfonos reacondicionados: entre lo nuevo y la segunda mano o, ¿mejor?
-

Bicicletas inteligentes ¿Qué son y cuál es su futuro?
-

Implementación del APPCC Cocina: Mejores Prácticas y Beneficios de la Consultoría APPCC